- SS: 有关基本算法或原理的文章,建议吃透
- S: 前沿顶刊文章,提出通用改进思路或算法创新
- A: 前沿顶刊文章,对某一问题提出针对性改进方法,但存在局限性或改进空间
- B: 非顶刊文章,可以参考
- C: 参考价值一般的文章
- O: 开源文章
论文记录2
| 论文名 | [出处]模型名 | 任务 | 核心技术 | 突出优势与存在问题 | 比对模型 | 数据集 | 评价指标 |
|---|---|---|---|---|---|---|---|
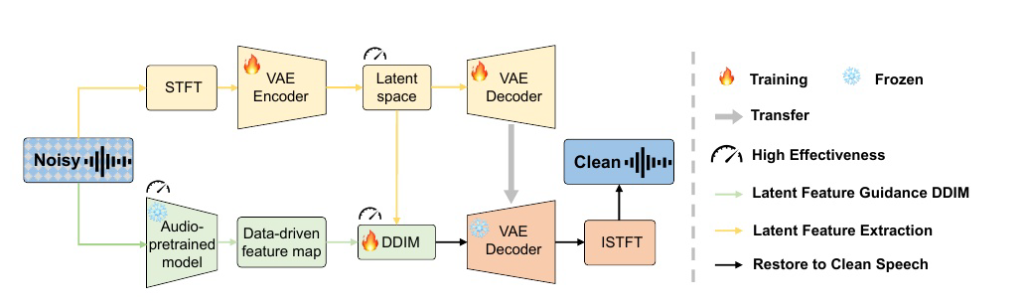
| (BO)Pre-training Feature Guided Diffusion Model for Speech Enhancement | [arxiv-2024.6.14] FUSE | 语音增强 | 创新点1:使用VAE提取隐空间特征,减少训练量 创新点2:使用预训练声学模型(BEATs)提取特征,并作为DDIM的条件项,引导扩散模型 创新点3:将训练好的VAE-Decoder权重冻结,接在DDIM之后 | 文中明确指出扩散模型的性能、效率、训练步骤和推理时间都阻碍了它们在语音增强中的表现,该方法主要是针对效率的改进 使用DDIM确实可以有效减少采样步骤,不知道SDE是否有对应的方法 | STCN/CDiffuse/DVAE/SGMSE/SGMSE+/MetricGAN+/Conv-TasNet | WSJ0-CHiME3/VB-Demand | POLQA PESQ ESTOI SI-SDR SI-SIR SI-SAR DNSMOS |
| (BO)Universal Speech Enhancement with Score-based Diffusion | [ICLR 2023] UNIVERSE | 广义语音增强 | 模型由生成器和调节网络组成(图1)。生成器网络由一个类似UNet的结构和中间的门控循环单元(GRU)组成。其模型结构经过了多重改进,最终选用了具有多头潜变量损失的条件网络 | 参数量很大 189M 模型表现高度依赖数据集质量 | – | 训练集似乎是自制16kHz音频 测试集VCTK-Demand | COVL STOI WARP-Q SESQA COMP |
| (A+O)A Variance-Preserving Interpolation Approach for Diffusion Models With Applications to Single Channel Speech Enhancement and Recognition | [TASLP 2024.6.12] VPIDM | 语音增强/ASR预处理 | 这个思路真的很妙! 1. 抛弃使用方差爆炸插值扩散模型VEIDM(SGMSE其实就是个典型的VEDIM),转而使用保方差插值扩散模型VPIDM 2. VEDIM去噪分数匹配的得分函数由插值变量构成,而不是完全干净语音X0 3. VEDIM的人工神经网络ANN估计并不准确,因此需要矫正器,而VPIDM只需要25个迭代步且无需矫正器 4. 在处理原始噪声语音时,人工神经网络(ANN)往往首先从噪声中估计出干净信号,然后再推导出高斯成分。虽然这种方法更简单,但可能会削弱ANN有效学习整个扩散过程的能力。VPIDM可以看作是在VPDM上应用插值方案。当没有目标噪声或插值系数为零时,VPIDM简化为VPDM,因此将VPDM定位为更广泛的VPIDM框架中的一个特例。 | 由于VEDIM的最终扩散结果实际上保留了初始干净语音的确定性信息,而实际推理时又使用带噪失真语音作为初始值,这样不可避免的存在初始误差 缺点: 1. 其把语音噪声完全假设为加性噪声,所做的插值也完全是线性插值。 2. 噪声淹没和确定性恢复是通过定制递增和递减函数实现的,这样有些不够严谨 | MP-SENet/MetricGAN+/NCSN++/SGMSE(VEIDM) | VB-Demand DNS CHiME-4 | PESQ ESTOI CSIG CBAK COVL |
| (B)Stimulating Diffusion Model for Image Denoising via Adaptive Embedding and Ensembling | [arXiv-2024.4.15] DMID | 图像去噪 | 提及了用GAN作去噪的缺点。以及使用无条件扩散模型解决线性图像恢复问题(y=Hx+n) 扩散模型作为高斯去噪处理器很优秀,但针对不遵循高斯分布的真实世界噪声则难以处理,为此其改进了噪声变换技术NN 通过多次 推断,使用预训练扩散模型生成多个去噪图像。最后,采用集成方法减少失真。 | 可惜是用DDIM做的 | |||
| (C)Deep neural network and noise classi cation-based speech enhancement | [TASLP 2018.11.1] | 语音增强 | 提出可以训练高斯混合模型GMM对加噪音频分类,通过多个高斯分布的加权和来表示数据分布的概率密度函数。判断噪声类型一般使用无语音帧作为输入,而无语音帧的判断是使用STFT熵H(t)来进行的,熵H(t)在语音缺失帧中具有更高的值。开始帧通常被认为是非语音帧。用开始帧的平均熵作为阈值来区分无语音帧和语音帧。这个思路或许可以采用 | 文中将噪声分为6类: Babble——人声密集的公共场所噪声 White——高斯白噪声 f16——航空环境噪声 hfchannel——无线电通信中的信道噪声 Pink——低频能量较高的噪声,如风声或雨声 Factory1——工业环境噪声 | |||
| (BO)TIME SERIES DIFFUSION IN THE FREQUENCY DOMAIN | [arxiv-2024.8.8] | 时间序列生成 | 提出了频域扩散模型,将扩散方程扩展到了频域形式(主要通过将布朗运动改造为镜像布朗运动),或许有参考性 | 在语音任务中是否适用还待测试 9.9更新:看了一下源码似乎只是对数据进行了dft变换,pass | |||
| (SR)A Survey on Diffusion Models for Time Series and Spatio-Temporal Data | [arxiv-2024.6.11] | 时间序列分析 | 非常好的文献,将目前针对时间序列分析的所有扩散模型 在模型方面分为非条件模型和条件扩散模型(更细分为基于概率的扩散模型DDPMs和基于分数的扩散模型ScoreSDEs) 在研究任务方面分为预测和生成两类(预测任务如回归和异常检测,生成任务如序列插补和增强) 在针对数据方面分为时间序列和时空数据 通过以上几种分类,可以将到目前的所有扩散模型进行汇总分析,分析了扩散模型在各类生成模型中的优势,并对未来研究方向进行展望 | 研究前景大致可以分为: 增强可扩展性和效率 改善鲁棒性和泛化能力 改进先验知识对生成的引导 进行多模态数据融合 大型语言模型与扩散模型集成 | |||
| (BO)DOSE: Diffusion Dropout with Adaptive Prior for Speech Enhancement | [NerulIPS 2024] | 语音增强 | 其基础结构基于DiffWave 其提到基于扩散的语音增强(SE)方法主要分为两大类: (1) 设计特定的条件注入策略,一般通过设计特殊的SDE(漂移项)来实现 (2) 利用辅助条件优化器生成语音。一般通过设计特殊网络结构实习 提到使用条件模型进行语音增强使可能出现的条件崩溃现象 | 总结:DOSE 具有三个重要优势:(1)通过完全舍弃 xt,使条件因素 y 成为“主角”,自动增强生成样本与条件因素之间的一致性。(2)通过使用修改后的训练目标对模型进行训练,DOSE 不仅在处理高斯噪声(xt→x0)时表现出色,还能够应对各种非高斯噪声(y→x0)。(3)DOSE 效率很高(仅需2步),比现有的扩散增强模型更快。 | DiffWave/DiffuSE/CDiffuSE/SGMSE/DR-DiffuSE | VB-Demand CHiME-4 | STOI PESQ CSIG CBAK COVL |
(BO)Pre-training Feature Guided Diffusion Model for Speech Enhancement
https://honda-fit.ru/forums/index.php?autocom=gallery&req=si&img=7031
http://wish-club.ru/forums/index.php?autocom=gallery&req=si&img=5359
Good https://is.gd/tpjNyL
http://toyota-porte.ru/forums/index.php?autocom=gallery&req=si&img=3387
https://vitz.ru/forums/index.php?autocom=gallery&req=si&img=4848
http://terios2.ru/forums/index.php?autocom=gallery&req=si&img=4752
https://vitz.ru/forums/index.php?autocom=gallery&req=si&img=5010
https://honda-fit.ru/forums/index.php?autocom=gallery&req=si&img=7239
http://terios2.ru/forums/index.php?autocom=gallery&req=si&img=4766
https://mazda-demio.ru/forums/index.php?autocom=gallery&req=si&img=6503
https://vitz.ru/forums/index.php?autocom=gallery&req=si&img=4984
http://terios2.ru/forums/index.php?autocom=gallery&req=si&img=4735
https://honda-fit.ru/forums/index.php?autocom=gallery&req=si&img=7117
http://toyota-porte.ru/forums/index.php?autocom=gallery&req=si&img=3293
OVERКАЙФ – Какие Пейзажи скачать и слушать онлайн https://shorturl.fm/WgfZo
Тима Белорусских – Незабудка (Ramirez & Rakurs Remix) скачать mp3 и слушать бесплатно https://shorturl.fm/YB4lg
Бэнг & Хоккеист – Майк’ский скачать и слушать песню бесплатно https://shorturl.fm/YmquF
Ми Ульяна – Ладони ( 2013 ) скачать mp3 и слушать бесплатно https://shorturl.fm/C7jnf
Мот – Перемены-это красиво скачать песню и слушать бесплатно https://shorturl.fm/sc09i
http://wish-club.ru/forums/index.php?autocom=gallery&req=si&img=5233
http://passo.su/forums/index.php?autocom=gallery&req=si&img=4272
https://honda-fit.ru/forums/index.php?autocom=gallery&req=si&img=7097
https://hrv-club.ru/forums/index.php?autocom=gallery&req=si&img=7044
http://wish-club.ru/forums/index.php?autocom=gallery&req=si&img=5369
https://mazda-demio.ru/forums/index.php?autocom=gallery&req=si&img=6598
http://toyota-porte.ru/forums/index.php?autocom=gallery&req=si&img=3295